March 16, 2025
Getting started with libbpf
In the previous article of this series, we wrote an eBPF program using the BCC
library. It simplifies our tasks significantly and abstracts away a lot of things.
This is the sample application we used last time:
from bcc import BPF
program = r"""
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b.trace_print()
As a summary, it has two sections overall, the actual eBPF program written in C,
and stored in a variable as a string. Then we have an overall python program, that
is doing three major tasks:
- compiling the
eBPFprogram. - getting the
hook pointwhere we attach oureBPFprograms. - attaching the program to that hook point.
- helper functions like
trace_print.
But there are many issues with this, which we will discuss in the next section where
we explain why to use libbpf
Libbpf
Libbpf is a C based library that takes compiled eBPF object files, prepares and
loads them into the Linux kernel. It abstracts the entire process that is needed
to manage the lifecycle of an eBPF program.
Now, let's try to understand what is the use of libbpf?
Why libbpf
Libraries like BCC make the process easier through their helper functions
and abstracted APIs, but they have following issues:
- Runtime Compilation:
BCCcompiles theeBPFprogram on every execution, which slows the startup times ofeBPFpowered software. - External Dependency: A product written using
BCCexpects presence of external dependencies likeLLVM,CLangandBCCitself already present on the system, which makes the overall delivery of the product harder. - Large Binary Sizes: Due to it's runtime compilation, a
BCCpowered solution often leads to large binary sizes which can lead to unwanted overhead. This is due to all the external dependencies that the program has to include in the binary itself. - Feature Delay:
eBPFis developed and maintained by the linux kernel hence there are new features and updates coming up regularly as a result of itBCCruns behind on the features provided by the kernel.
libbpf on the other hand solves all these problems, and provides a lightweight,
robust, bleeding-edge solution of building eBPF powered solutions. This is
due to the following reasons:
- Ahead of Time Compilation:
libbpfallows for ahead-of-time compilation, where BPF programs are compiled before runtime. This approach significantly reduces execution time and eliminates the need for runtime compilation, improving performance. - No External Dependency: By compiling
eBPFprograms ahead of time,libbpfremoves the need for external tools likeClangandLLVMat runtime. This simplifies deployment, as users do not need to ensure these tools are installed on the target system, reducing setup complexity and enhancing usability in production environments. - Small Binary Sizes: Since the final product to be run on the end-user's system does not contain any external dependencies, the final Binary is extremely lightweight.
- No Feature delays:
libbpfis developed as a part of the Linux kernel itself, hence it is always up to date with any new upcoming features. - Enhanced Portability:
libbpfsupportseBPF CO-RE (Compile Once - Run Everywhere), which enhances the portability ofeBPFprograms across different kernel versions. This feature allows programs to be compiled once and run on various kernels without needing runtime adjustments, addressingBCC's compatibility challenges.
With that we understand how building an eBPF solution using libbpf has a
technological edge over using BCC. Next, we will try to build a mental model
of the life cycle of an eBPF program.
Now we understand the major difference between BCC and libbpf why major
companies like AquaSecurity
are moving away from BCC to libbpf for their major projects
like tracee. So, this next section will
be about understanding how can you write your own eBPF powered products
using libbpf.
First, let's review what the life-cycle of an eBPF program looks like, then we
will look at the features libbpf provides to ease the process.
Life Cycle of an eBPF program
The life-cycle of an eBPF program mainly contains 4 steps.
- Open Phase:
eBPFobject file is parsed,eBPFmaps and global variables are discovered. - Load Phase:
eBPFmaps are created, variouseBPFprograms are relocated, verified and loaded into the kernel. - Attachment Phase:
eBPFprograms that have been previous loaded into the kernel are now attached to theeBPFhooks (tracepoints,kprobes,cgroupsetc.). Now theeBPFprograms are actually running and performing their work. - Tear Down Phase: Resources used by
eBPFare freed up by destroying theeBPFmaps and detaching + unloading theeBPFprograms from the kernel.
[!NOTE] In C programming, an object file is an intermediary file generated after compiling a source code file. It contains machine code, data, and metadata but is not directly executable.
To make handling of the entire life-cycle easier, libbpf introduces the concept
of skeleton files that simplify the writing and distribution of your product
10x better.
Skeleton Files
Skeleton files in libbpf are a powerful feature designed to simplify the
development and integration of eBPF programs into user-space applications,
particularly those written in C.
When a developer writes a eBPF program and compiles it into an object file
(e.g., myprog.bpf.o), they can use a tool like bpftool to generate a skeleton
file (e.g., myprog.skel.h). This generated C header file encapsulates all
the necessary code to interact with the eBPF program.
You can think of skeleton skeleton as an alternative interface to libbpf APIs
for working with eBPF objects since it provides 4 major APIs for each phase
of the life-cycle of en eBPF program.
<name>__open(): creates and openseBPFapplications.<name>__load(): instantiates, loads and verifieseBPFapplication parts.<name>__attach(): attaches the auto-attachableeBPFprograms.<name>__destroy(): detaches theeBPFprogram and frees up all the space.
[!NOTE] Replace
<name>with the actual name of youreBPFobject.
Additionally, the skeleton provides easy access to eBPF maps and global
variables defined in the program, such as through a function like
myprog_bpf__my_map() or a structure field like skel->bss->my_var.
This eliminates the need for developers to write repetitive boilerplate code,
reducing both development time and the potential for mistakes.
It's understandable if you cannot grasp how each individual function and feature
works, in the next article we will write an entire eBPF powered program on
our own using C and libbpf, things will be more clearer then.
So, if we combine both user-space and kernel-space programs, the most minimal
program would look like this.
User Space Program
The user space application is responsible for leveraging libbpf in order to
manage the entire life-cycle of the eBPF(kernel-space) program. Below is an
example with detailed comments (You don't have to understand every line of the
program).
/* minimal.c */
// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause)
/* Copyright (c) 2020 Facebook */
/* Include the required header files */
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "minimal.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct minimal_bpf *skel;
int err;
/* Set up libbpf errors and debug info callback */
libbpf_set_print(libbpf_print_fn);
/* Open eBPF application */
skel = minimal_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* ensure eBPF program only handles write() syscalls from our process */
skel->bss->my_pid = getpid();
/* Load & verify eBPF programs */
err = minimal_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* Attach tracepoint handler */
err = minimal_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
/* trigger our eBPF program */
fprintf(stderr, ".");
sleep(1);
}
cleanup:
minimal_bpf__destroy(skel);
return -err;
}
Kernel Space Program
The below program is pretty straight-forward. This program monitors the write
syscall and logs a message when it is called by a process with a specific PID
set in the my_pid variable.
/* minimal.bpf.c */
// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause
/* Copyright (c) 2020 Facebook */
/* include the necessary header files */
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
int my_pid = 0;
SEC("tp/syscalls/sys_enter_write")
int handle_tp(void *ctx)
{
int pid = bpf_get_current_pid_tgid() >> 32;
if (pid != my_pid)
return 0;
bpf_printk("BPF triggered from PID %d.\n", pid);
return 0;
}
Actually, there are many things that might be confusing you, like what is that
SEC section? Why is it specifying the license? And what does the string
tp/syscalls/sys_enter_write mean here?
All these questions will be answered in the section where we will write our programs from scratch, there we will explain things like:
- Program Types and ELF sections.
- How do we know the exact
tracepointwhere we want to attach oureBPFprograms and how to telllibbpfwhere to actually attach the program (i.e. on which hook point). - Types of maps and how do we decide which map is the best for our use case.
So, if we properly load the above program into the kernel, we expect the following behaviour.
- User space program triggers the kernel program.
```c
for (;;) {
/* trigger our eBPF program */
fprintf(stderr, ".");
sleep(1);
}
- Kernel Space program writes to
sys/kernel/debug/tracing/trace_pipefile.
bpf_printk("BPF triggered from PID %d.\n", pid);
- Read the data written by the kernel program using
sudo cat sys/kernel/debug/tracing/trace_pipe. The output looks something like this.
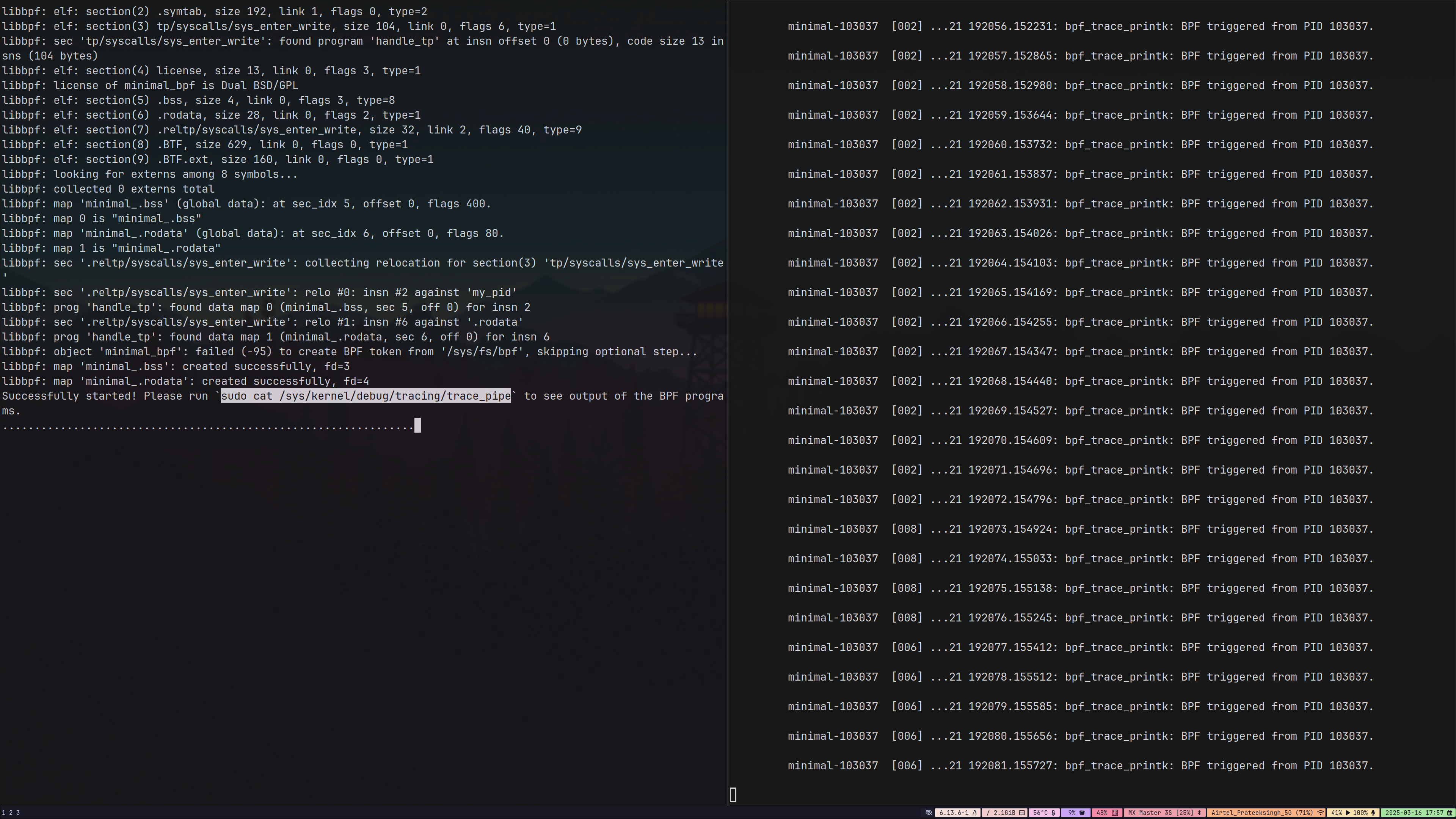
There is a reason I haven't told you to run these programs on your system as of now,
this is because running eBPF programs using libbpf requires some configurations
to make the entire thing work, which we will look out in the next article.
Conclusion
In conclusion, transitioning from BCC to libbpf offers several advantages, including improved performance, smaller binary sizes, and simplified deployment, all while staying up to date with the latest kernel features. libbpf allows for ahead-of-time compilation, eliminating the need for runtime dependencies like LLVM and Clang, which not only enhances portability but also reduces the complexity of distributing eBPF-powered solutions. By leveraging the life-cycle management features provided by libbpf, such as skeleton files and easy-to-use APIs, developers can build more efficient and scalable eBPF programs. In the next article, we will dive deeper into writing custom eBPF programs using libbpf, providing practical insights into its capabilities and workflow.
In the next article, we will setup our system to start writing our own eBPF programs
from scratch. Stay Tuned.